Streaming video understanding requires models not only to process temporally incoming frames, but also to anticipate user intention for realistic applications like AR glasses.
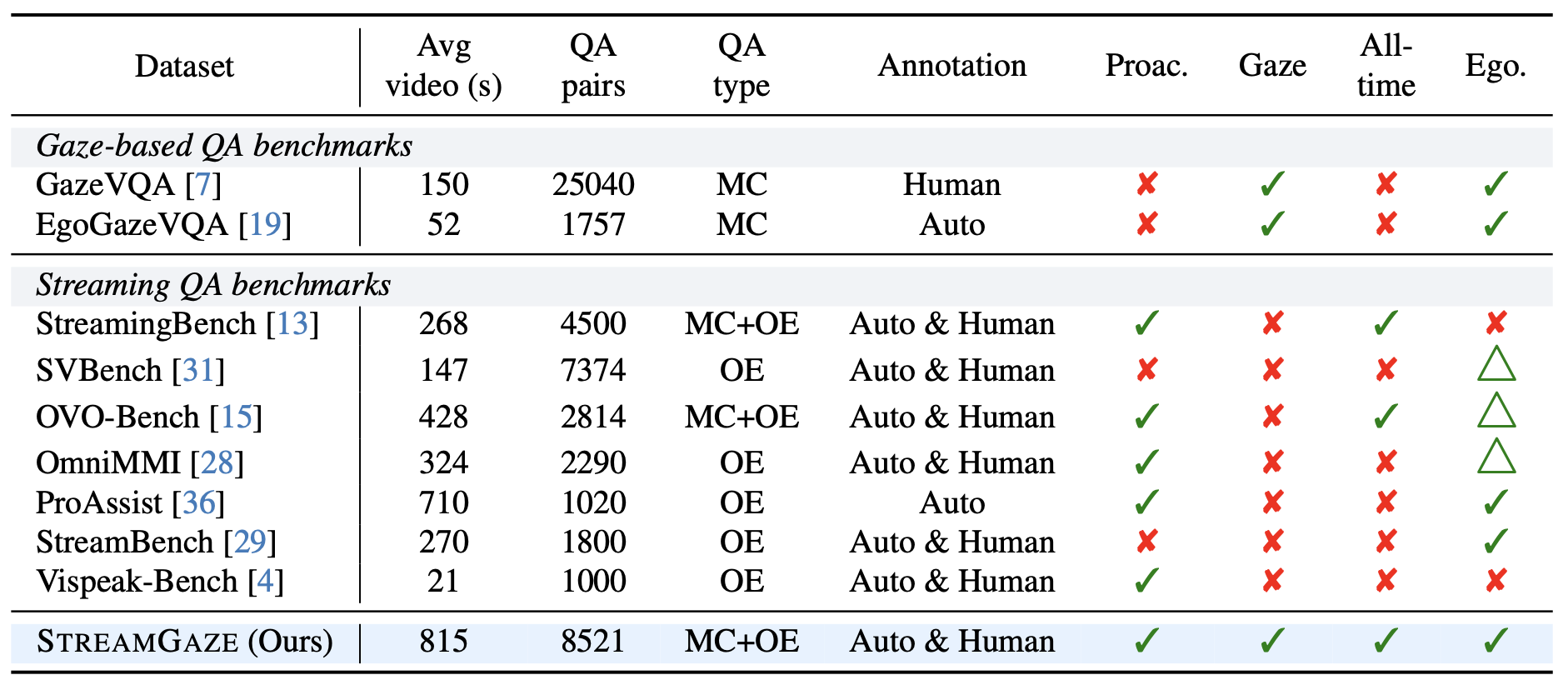
While prior streaming benchmarks evaluate temporal reasoning, none measure whether MLLMs can interpret or leverage human gaze signals within a streaming setting.
To fill this gap, we introduce StreamGaze, the first benchmark designed to evaluate how effectively MLLMs use gaze for temporal and proactive reasoning in streaming videos.
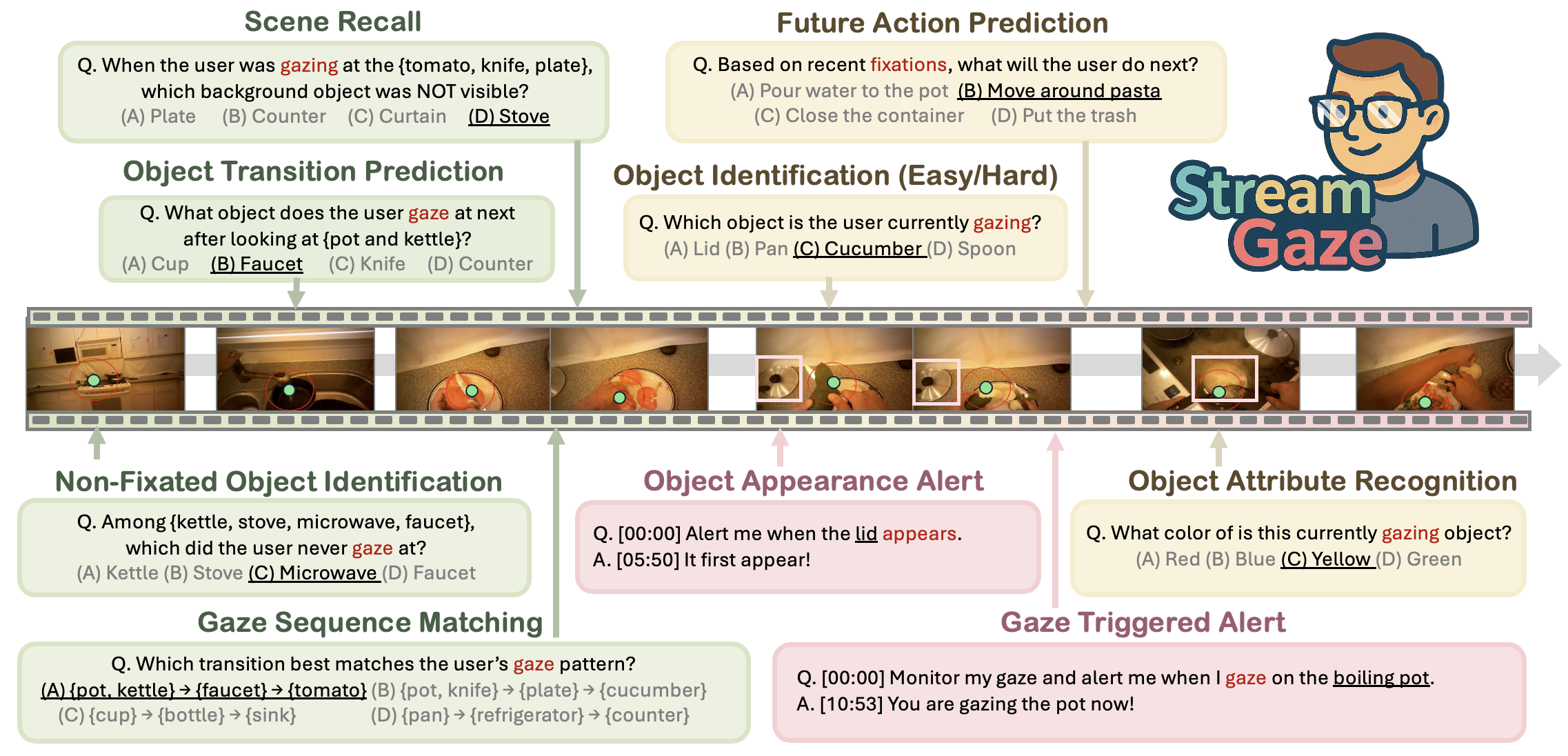
StreamGaze introduces gaze-guided past, present, and proactive tasks that comprehensively evaluate streaming video understanding.
These tasks assess whether models can use real-time gaze to follow shifting attention and infer user intentions from only past and currently observed frames.
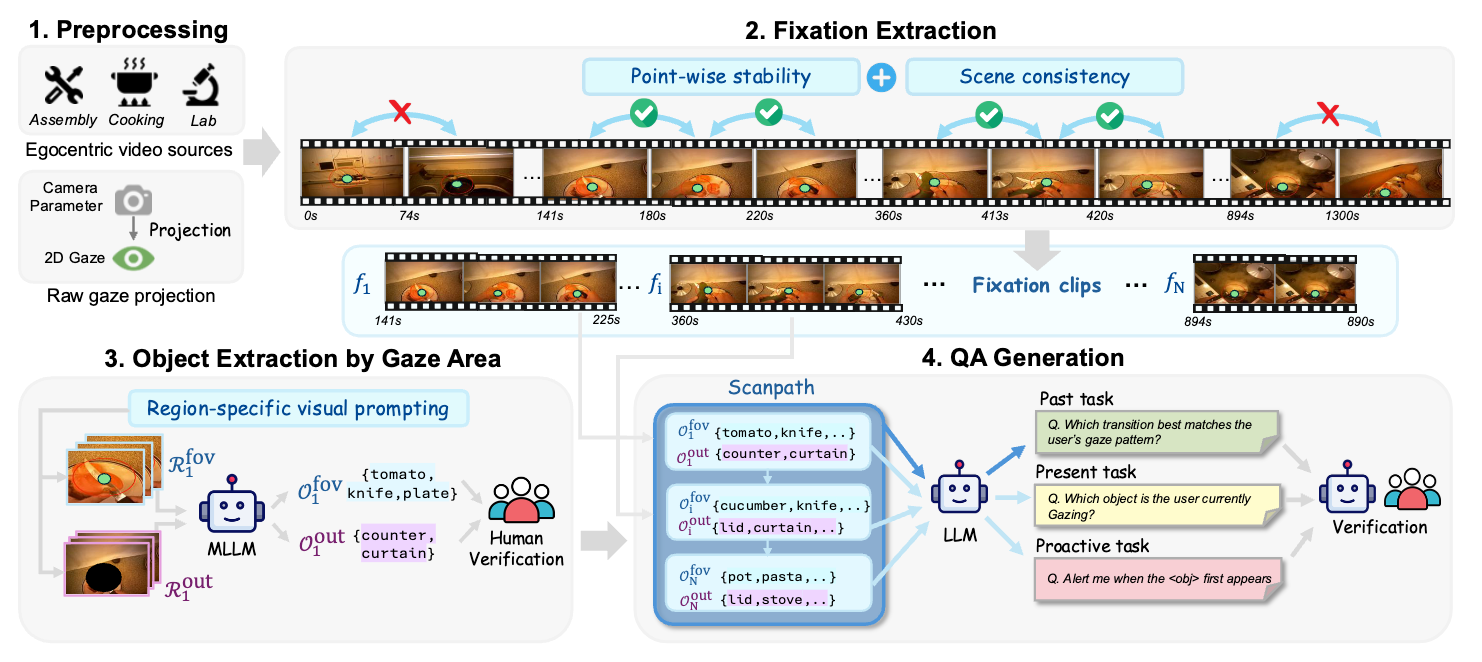
To build StreamGaze, we develop a gaze-video QA generation pipeline that aligns egocentric videos with raw gaze trajectories via fixation extraction, region-specific visual prompting, and scanpath construction.
This pipeline produces spatio-temporally grounded QA pairs that closely reflect human perceptual dynamics.
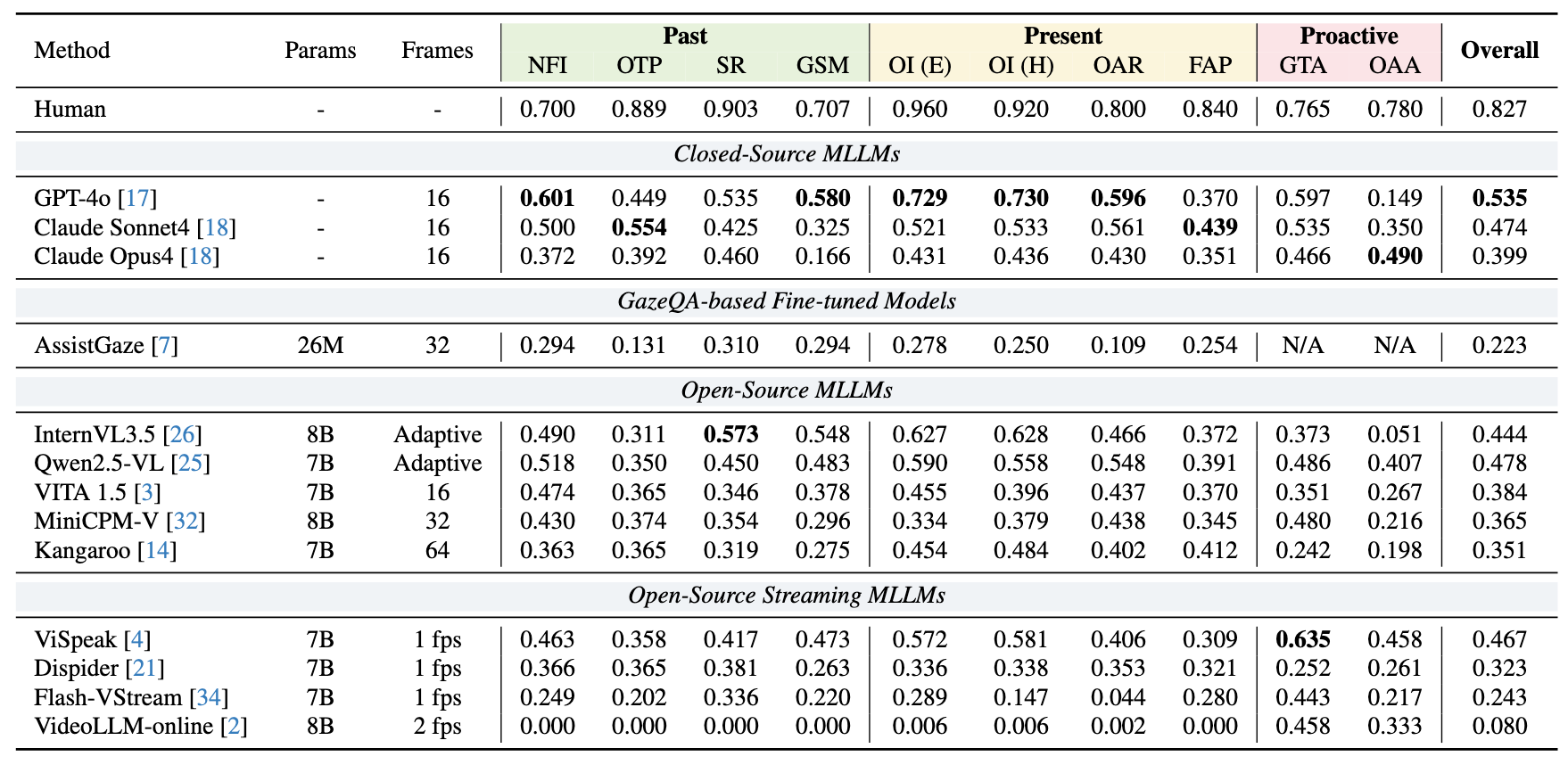
Across all StreamGaze tasks, we observe substantial performance gaps between state-of-the-art MLLMs and human performance, revealing fundamental limitations in gaze-based temporal reasoning, intention modeling, and proactive prediction.